GenAI, machine learning, deeplearning, datascience, big data… des termes que l’on retrouve partout dans les médias et dans le monde professionnel aujourd’hui autour de la donnée. Si ces solutions semblent si intéressantes, leurs mises en production restent encore limitées. Aujourd’hui 70% des projets d’intelligence artificiel sont des échecs. Les raisons avancées sont multiples : mauvais cas d’usage, mauvaise communication, management non aligné sur le livrable du projet, quantité de données et qualité des données insuffisantes, …
Dans cet article nous nous concentrerons sur la quantité et la qualité des données. Après tout, un projet d’IA c’est de la donnée et même si l’IA a beaucoup de vertu, « garbage in / garbage out »* reste malheureusement vrai. Un projet de data science c’est 80% du temps à travailler sur la collecte de données, son nettoyage et sa mise en forme avant de pouvoir passer à la modélisation.
Les entreprises doivent assurer qualité et disponibilité des données si elles souhaitent mettre en production ce type de projet avec leurs propres données. Très souvent nous retrouvons les mêmes questions : « Qui a la donnée ? Où est-elle stockée ? Est-ce que la donnée a été modifiée ; si oui comment ? ». Ces questions ralentissent les projets ou peuvent dans certains cas les arrêter ou les mettre en pause. La mise en production de modèles requiert un niveau de disponibilité supérieur. Les chaînes de traitement doivent être automatisées et ne peuvent pas être interrompues. C’est pourquoi un data stack avec des référentiels de données bien définie et maitrisés est indispensable.
Data stack
Mais alors qu’est-ce qu’un data stack ? Un data stack est un ensemble d’outils et de technologies qui permet de collecter, traiter et mettre à disposition les données dans une organisation. Chaque outil/technologie peuvent être représentés par un bloc fonctionnel interagissant avec la donnée. La maîtrise de ces blocs par les entreprises est primordiale pour assurer qualité et disponibilité des données. C’est la fondation d’un projet data. Maîtriser son data stack avant de se lancer sur de l’IA est fondamental. On ne commence pas une maison par le toit !
Sur LinkedIn vous trouverez tous les jours des postes de personnes mettant en lumière les data stacks de différentes entreprises. Comme des passionnés automobiles ils relèvent le capot du moteur et décrivent chaque bloc fonctionnel en identifiant les technologies/fournisseurs de services. Pour vous aider à y voir plus clair nous vous proposons un exemple de schéma de modern data stack que nous décrivons bloc par bloc.
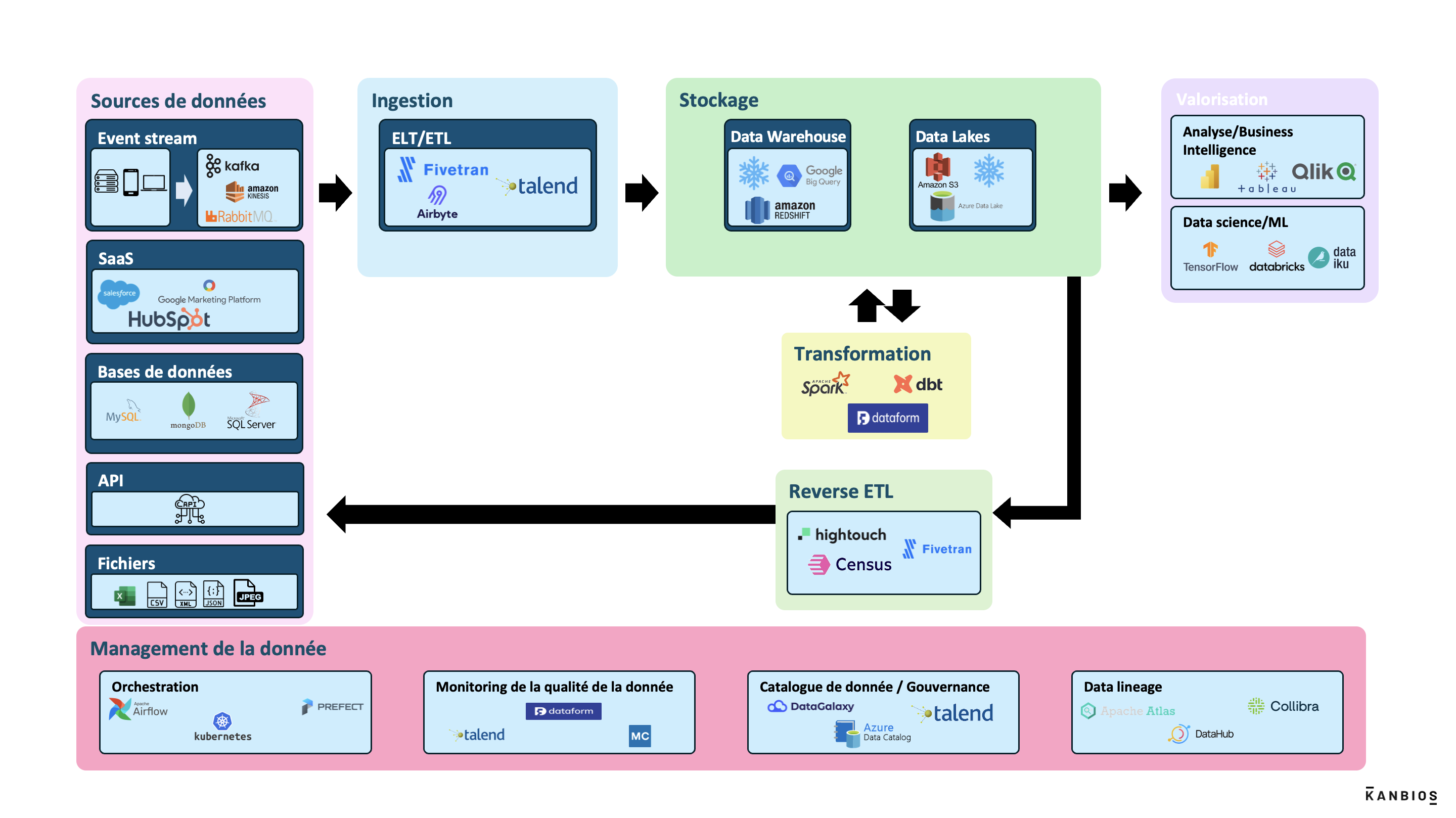
Sources de données
Les sources de données peuvent être des :
- Event stream: fourni des informations sur des actions et des occurrences à mesure qu’elles se produisent en temps réel. Ces flux continus de données, sont souvent utilisés pour traiter et analyser des informations instantanément
- SaaS: logiciels disponibles à la demande via Internet
- Bases de données: système de stockage d’information
- API (Application Programming Interface): ensemble de règles et de protocoles permettant à des applications différentes de communiquer entre elles et d’échanger des données de manière structurée et sécurisée.
- Fichiers : données structurées (Excel, csv, xml, …), non structurées (images, vidéos, …), semi-structurées (JSON)
Ingestion
Ces données (sources de données) sont ingérées par la modern stack via un ETL ou ELT. Un ETL ou un ELT a pour objectif de transporter la donnée d’une source à une zone de stockage. L’ELT (Extract Load Transform) fait une copie de la source de donnée (sans la modifier) dans la zone de stockage. L’ETL (Extract Transform Load), lui, applique des transformations sur la donnée avant son stockage. Aujourd’hui le stockage ne coute plus grand-chose en comparaison à il y a quelques années. Les solutions d’ELT sont donc privilégiées et permettent d’avoir l’ensemble des données brutes à disposition.
Stockage
Après avoir été transportées par un ELT/ETL les données sont stockées dans les modern stack via :
- Des Data Warehouses: système centralisé de stockage de données structuré, optimisé pour les requêtes et l’analyse, permettant de prendre des décisions basées sur des données historiques.
- Des Datalakes: dépôt de stockage où de grandes quantités de données brutes et non structurées sont conservées, permettant une analyse flexible et diverses transformations de données.
- Data mesh : architecture décentralisée qui organise les données par domaine d’activité et permet une utilisation en libre-service dans toute l’organisation en transférant la propriété des données aux producteurs. Cette approche favorise l’utilisation de technologies cloud natives.
Transformation
Durant cette phase, nous avons le nettoyage des données brutes, leur structuration et leur augmentation. Nous retrouvons les notions de qualification des données en Bronze, Silver ou Gold.
- Bronze: données brutes collectées directement à partir de différentes sources sans aucune transformation ou nettoyage.
- Silver: données semi-traitées qui ont subi un nettoyage initial et des transformations de base.
- Gold : données finales, hautement transformées et optimisées pour des analyses spécifiques ou des rapports.
Valorisation
Une fois la donnée stockée, nettoyée, augmentée vient l’étape de valorisation et la question comment créer de la valeur à partir de la donnée mise à disposition ?
- L’analyse/Business Intelligence: techniques statistiques et outils de visualisation pour identifier des tendances, des motifs, des anomalies dans les données. La Business Intelligence aide surtout à prendre des décisions stratégiques éclairées et rationnelles basées sur la donnée.
- Data science/ML : algorithmes de prédiction (ex : vente), catégorisation (ex : clients), optimisation (ex : trajet entre deux points). La GenAI (chatgpt) est basée sur des algorithmes de machine learning.
Reverse ETL
La dernière étape qui peut intervenir après le stockage est le Reverse ETL qui extrait des données analysées et les intègre dans des systèmes où elles peuvent être utilisées pour des actions concrètes, comme personnaliser des campagnes marketing ou améliorer l’engagement client.
Management de la donnée
Finalement en parallèle de toutes ces étapes interviennent des fonctions transversales :
- Gouvernance : régit la gestion et l’utilisation des données au sein d’une organisation. Elle vise à garantir la qualité, la sécurité, la confidentialité, l’intégrité et la disponibilité des données.
- Orchestration: automatise et gère l’exécution de flux de travail de données (pipelines de données). Il coordonne les différentes étapes du processus de traitement des données.
- Monitoring de la qualité de la donnée : surveillance continue des données pour s’assurer qu’elles répondent aux normes et critères définis par l’entreprise
- Catalogue de donnée: un catalogue de données est une plateforme ou un système centralisé qui répertorie et décrit les ensembles de données disponibles au sein d’une organisation. Il fournit des métadonnées détaillées sur chaque jeu de données, telles que leur origine, leur structure, leur propriétaire, leur date de création,..
- Data lineage: outil pour suivre et comprendre le parcours d’une donnée depuis sa source initiale jusqu’à son utilisation finale
Tous ces blocs forment un modern data stack. Il est important pour une entreprise de connaître et maîtriser son infrastructure data pour assurer un service de qualité et éviter de travailler en silo avec des outils qui ne pourront jamais communiquer entre eux.
Et vous où en êtes-vous dans vos projets Data ? Kanbios expert en data et digital vous accompagne sur toute votre chaine de valeur quelle que soit l’ampleur de votre projet.
*« garbage in/ garbage out » un principe informatique qui stipule que des données erronées ou de mauvaise qualité en entrée d’un système produiront inévitablement des résultats erronés ou de mauvaise qualité en sortie.
